

In the digital age, where information is abundant and constantly evolving, the ability to extract and analyze data from the vast expanse of the World Wide Web has become a crucial skill.
Web scraping, often considered the digital equivalent of harvesting, is the process by which data is collected from websites and transformed into a structured format for various purposes.
From $2.9 billion in 2022, the web scraping industry is projected to reach $4.9 billion by 2027. Interestingly, the online eCommerce industry accounts for around half of all web scraping usage.
Some credible sources claim that the annual income of a web scraper averages a whopping $58,000.This remuneration is commensurate with the market value of web scrapers and is thus competitive.
Whether you’re a data enthusiast, a business seeking market insights, or a researcher looking for valuable information, understanding what web scraping is and how it works is essential to harnessing the power of the internet’s wealth of data. In this exploration, we will delve into the concept of web scraping, its applications, and the tools and techniques that enable this remarkable practice to thrive in the information-driven landscape of the internet.
How Web Scraping Works
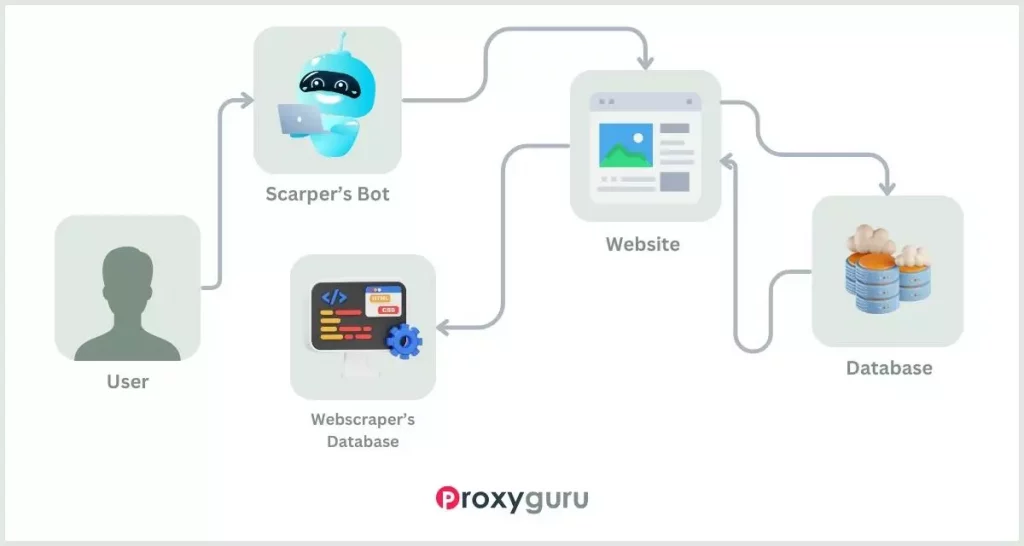
Think of web scraping like a step-by-step recipe. It has specific stages that need to be followed in order to get the desired information from a website.
Sending HTTP Requests
A web scraper starts by asking a website nicely for a specific page’s content. It does this by sending a special kind of message, called an HTTP request, to the website’s computer. Think of it like sending a letter to ask for information.
This is usually done using special computer programs (like Python ‘requests’ library) that know how to send these requests and receive the website’s response.
Fetching HTML Content
Once the web scraper asks for a web page’s content, the website’s computer responds by giving it the page’s code. This code, called HTML, is like the instructions that tell a web browser how to display the text, pictures, links, and everything else on the webpage. It’s like the recipe for building the webpage you see.
Parsing HTML
To understand and work with the HTML code, web scrapers rely on special tools, like BeautifulSoup in Python. These tools help them organize the messy HTML code into a neat and organized structure, like sorting your toys into different boxes so you can find them easily.
Extracting Data
After making the HTML code neat and tidy, web scrapers use special methods to find and pick out the exact pieces of information they want, like finding specific items in a store. These pieces can be text, pictures, links, tables, or anything else they’re looking for on the webpage.
Storing Data
Once they’ve gathered the information they need, they save it in different ways, like making lists, creating organized files, or using special storage places, depending on what they want to do with it later. It’s a bit like putting your toys in different containers based on their shapes and sizes.
Iterating and Pagination
In some web scraping jobs, you have to go through lots of pages to gather all the information you want. Scraping tools are like little robots that can do this job automatically, like turning the pages of a big book one by one to read the whole story.
Applications of Web Scraping
Market Research
Online stores use web scraping to get information about products, their prices, and what customers are saying about them from websites of their rivals.
Content Aggregation
Websites that gather news and interesting articles use web scraping to pull stories from various places on the internet and put them all in one spot for people to read.
Competitor Analysis
Businesses look at what their competition is doing on their websites to understand how much they charge for things, what products they sell, and what’s popular in the market.
Data Analysis
People who study things and make reports or decisions use web scraping to collect the information they need. For example, they might scrape data about stocks, weather, or people’s feelings on social media.
Lead Generation
Sales and marketing experts use web scraping to find and save contact details from websites so they can reach out to potential customers and build connections.
Ethical Considerations
While web scraping offers tremendous benefits, it’s essential to tread carefully and responsibly. Some ethical considerations include
- Respecting Terms of Service: Many websites have terms of service or robots.txt files that outline scraping restrictions. Scrappers should always respect these rules.
- Data Privacy: Scrappers must be cautious about handling personal data and ensure compliance with data protection regulations like GDPR.
- Server Load: Excessive scraping can overload a website’s server, causing disruptions. Responsible scrapping involves setting reasonable limits on the number and frequency of requests.
What kind of data do you scrape from the Web?
If you can see information on a website, you can usually collect it with web scraping. Organizations often gather things like pictures, videos, words, details about products, what customers think and say (like on Twitter or review sites), and prices from comparison websites. But remember, there are rules about what you can and can’t scrape, which we’ll talk about later.
How Can I Prevent My Website’s Content From Being Scraped?
Preventing your website’s content from being scraped entirely is challenging because determined individuals or bots may still find ways to access and scrape it. However, you can implement measures to deter or slow down scrapers and protect your content:
- Use a robots.txt file to specify which parts of your site should not be crawled.
- Implement CAPTCHA challenges to verify human users.
- Limit requests from the same IP address or user agent.
- Consider providing controlled access to your data via an API.
- Use anti-scraping services or tools to detect and mitigate scraping.
- Filter or block known scraper User-Agents.
- Implement session management and expiration.
- Obfuscate your HTML and JavaScript code.
- Monitor access logs for suspicious activity.
- Consider legal measures against malicious scrapers when necessary.
Why do we use web scraping?
Web scraping is a versatile technique used across various industries and fields to extract valuable data from websites efficiently. Organizations and individuals employ web scraping to collect data for diverse purposes, such as market research, competitive analysis, and lead generation. It provides insights into market trends, consumer behavior, and industry developments by gathering information from online sources.
Businesses can monitor competitors, adjust pricing strategies, and aggregate content from multiple websites to stay competitive. Additionally, web scraping is vital for financial analysis, academic research, weather forecasting, and accessing government and public data. It aids in healthcare research, job market insights, social media monitoring, sports analytics, and the aggregation of educational resources.
While web scraping offers numerous benefits, it’s essential to use it responsibly, respecting legal regulations and website terms of service to avoid potential ethical and legal issues.
Is web scraping legal?
Some people might worry that web scraping is like taking something that doesn’t belong to you. But the good news is, web scraping is usually legal. When a website puts information out there for everyone to see, it’s generally okay to scrape that data.
For instance, if Amazon shows product prices to anyone who visits their site, you can scrape that price data legally. Many apps and browser extensions do this to help shoppers find the best deals.
However, not all web data is meant for everyone. If you try to scrape personal info or things like copyrighted content, that’s a no-go. It can get you in trouble, even a DMCA takedown notice kind of trouble. So, always be careful about what you’re scraping!
FAQs
How can I learn web scraping?
You can learn web scraping through online tutorials, courses, and by practicing with real websites. Python is a popular programming language for web scraping, so learning Python is often a good starting point.
Can web scraping be used for illegal activities?
Yes, web scraping can be misused for illegal activities such as data theft, spamming, or unauthorized access to secure information. It’s essential to use web scraping responsibly and within legal boundaries.
What is the difference between web scraping and web crawling?
Web scraping focuses on extracting specific data from web pages, while web crawling involves navigating through websites to index or collect data. Web scraping is a subset of web crawling.
Is web scraping ethical?
Ethical concerns arise when web scraping is used to access sensitive or personal data without consent. Ethical scraping involves respecting the privacy and terms of the websites being scraped.
What tools or libraries are commonly used for web scraping?
Common tools and libraries for web scraping include Python libraries like Beautiful Soup, Scrapy, and Requests, as well as commercial tools like Octoparse and ParseHub.
What are the challenges of web scraping?
Challenges include handling dynamic websites, dealing with anti-scraping measures, respecting website robots.txt files, and maintaining scraping code as websites change.
Is there a limit to the amount of data I can scrape from a website?
Some websites may have rate limits, data volume restrictions, or block IP addresses that scrape too aggressively. It’s important to check a website’s terms of service and robots.txt file for guidelines on scraping.
What are the best practices for web scraping?
Best practices include respecting a website’s terms of service, avoiding overloading their servers, using appropriate headers, and handling errors gracefully. Additionally, regularly update your scraping code to adapt to website changes.
Over to You
Being the process of extracting data from websites using automated tools, web scraping is definitely a powerful technique that can be used for a variety of purposes, such as data mining, data analysis, and machine learning.
It is legal in most cases, but it is important to be respectful of the websites you are scraping and to avoid scraping too much data or causing the website to slow down. But proxy websites that you use for scraping ask you before hand the reason and the websites you are looking to consider for the web scraping.
If you are looking to scrape data online, you may need the right tools, proxies, and sound knowledge of the integration process.
